Aide à la décision clinique basée sur l’IA
Les systèmes d’aide à la décision clinique peuvent désormais s’appuyer sur l’intelligence artificielle pour accompagner et épauler toute prise de décision. Le domaine Développement numérique, données et qualité (DDQ) de la FMH passe en revue les points les plus importants à prendre en compte.
Le système de santé constitue l’une des sources de données les plus vastes et les plus importantes au monde [1]. Ces données peuvent non seulement servir à améliorer la prise en charge et la sécurité des patients, mais aussi la recherche et la formation. Pour analyser de grandes quantités de données médicales et identifier des modèles, il est indispensable de recourir à des technologies qui s’appuient sur l’intelligence artificielle (IA). Les systèmes d’aide à la décision clinique (SADC) basés sur l’IA peuvent soutenir les médecins dans leur prise de décision au quotidien [2-7]. Le présent article traite des avantages, des défis, des perspectives et des risques liés à ces modèles.
Systèmes d’aide à la décision clinique basés sur l’IA
Les systèmes d’aide à la décision clinique basés sur l’IA sont entraînés avec des données pour reconnaître des modèles et des caractéristiques et les mettre en relation (voir encadré). Ils utilisent des probabilités et des méthodes d’apprentissage automatique pour traiter de grandes quantités de données [3, 8, 9]. Ces systèmes se nourrissent de données cliniques qui proviennent de sources structurées (comme les résultats de laboratoire) ou non structurées (p. ex. rapports médicaux ou données d’imagerie médicale).
Les SADC basés sur l’IA se distinguent des modèles de langage génératifs tels que GPT, Gemini, LLaMA, etc., par leur visée, leur architecture et leur utilisation dans le contexte clinique [10]. Les modèles de langage génératifs sont certes utiles pour fournir des informations médicales et aider à clarifier le contexte, mais ils ne sont pas conçus pour interpréter les résultats de laboratoire, évaluer les facteurs de risque individuels ou analyser des images, et ils ne sont pas non plus homologués en tant que dispositifs médicaux.
Avantages de l’IA dans les SADC
L’intégration de l’IA dans les systèmes d’aide à la décision clinique peut améliorer la précision et l’efficacité des décisions médicales de différentes manières (Tab. 1). Leur principal bénéfice semble être un gain de temps (notamment en dermatologie ou en radiologie) et une plus grande cohérence des décisions cliniques [9]. Des études montrent toutefois que leurs bénéfices peuvent varier selon l’objectif visé, le moment ou le contexte (discipline et outil utilisé) dans lequel ils sont employés [11].
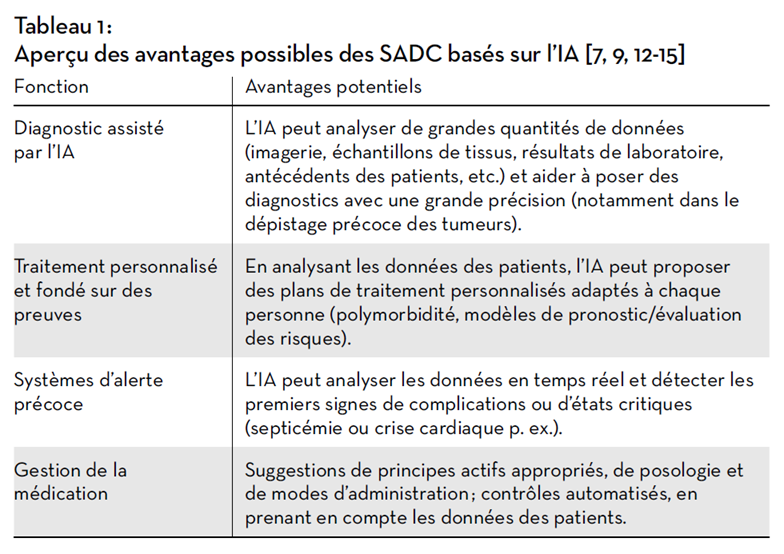
Défis liés aux SADC basés sur l’IA
Certaines incertitudes subsistent cependant (Tab. 2), dont le manque de transparence et d’explicabilité de ces systèmes (certains fonctionnent comme des « boîtes noires ») [16]. Autrement dit, il est difficile de comprendre comment le système arrive à la recommandation qu’il propose [4].
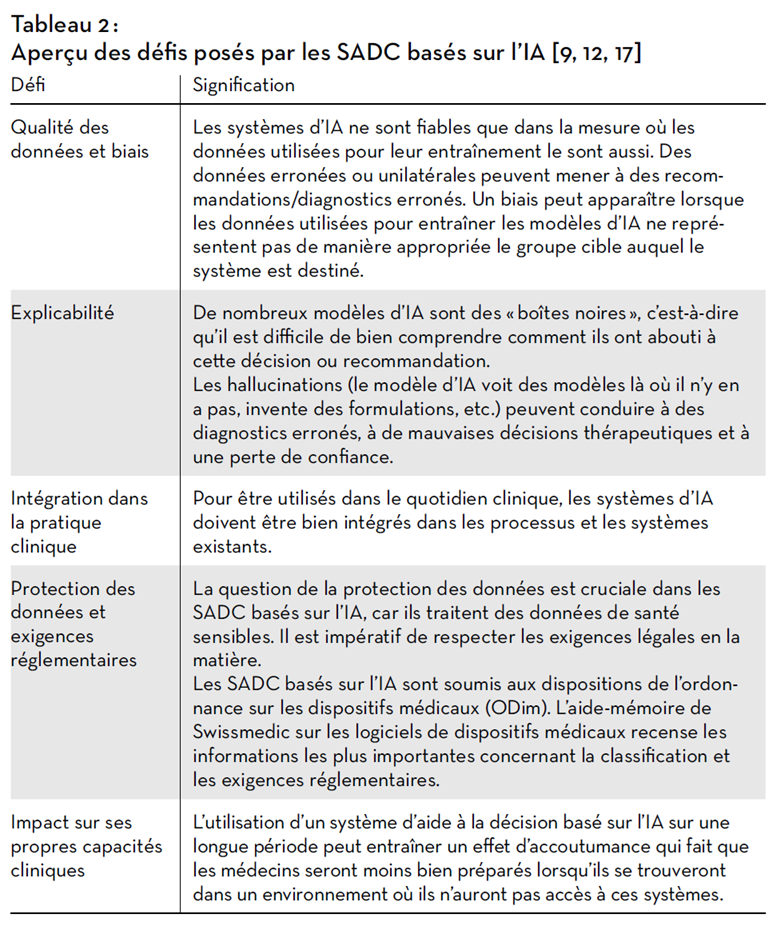
Implémentation
Les SADC basés sur l’IA sont des systèmes complexes qui comportent des risques. Seuls les systèmes dont la fiabilité et l’efficacité ont été prouvées et qui sont homologués en tant que dispositifs médicaux peuvent être utilisés dans la pratique clinique. Ils visent à assister les utilisatrices et les utilisateurs dans leur travail, mais ne les remplacent pas ; il est donc important de comprendre comment ils fonctionnent. Pour qu’ils soient mieux acceptés, les SADC basés sur l’IA doivent répondre à un besoin concret et être adaptés aux processus de travail [4, 18-20]. Il existe différents outils pour évaluer leur utilisabilité et convivialité (p. ex. la liste d’évaluation de l’IA digne de confiance pour l’autoévaluation [ALTAI], l’échelle Health-ITUES [Health-IT Usability Evaluation Scale]). Le tableau 3 présente quelques exemples de critères d’évaluation.

Aspects juridiques
Les données de santé sont des données sensibles. Le respect du cadre juridique et réglementaire est indispensable pour protéger la vie privée, la confidentialité et la sécurité des données des patients. Les réglementations relatives à l’autorisation des SADC basés sur l’IA posent des défis aux organisations de santé et aux fournisseurs de ces technologies [21, 22]. Les modèles d’IA (notamment l’apprentissage profond ou deep learning) traitent les données de manière moins transparente que les systèmes classiques, ce qui fait qu’il est plus difficile de respecter les obligations d’informer et de limiter la finalité pour laquelle les données de santé sont prélevées. Une anonymisation insuffisante (en particulier lorsque de nombreuses sources de données sont combinées), l’absence de contrôle de l’accès, un enregistrement non sécurisé, etc., peuvent engendrer une violation de la protection des données.
En intégrant l’IA dans les SADC, l’interaction entre médecin et patient devient une triangulation. Cela soulève des questions quant à la responsabilité et à la nécessité d’instaurer un cadre réglementaire pour l’utilisation de l’IA dans le secteur de la santé [4, 13]. En principe, cette
dernière peut soutenir les médecins et leur donner des idées, mais la responsabilité de leurs décisions leur revient et ils doivent pouvoir les justifier.
Perspectives
La technologie RAG (Retrieval-Augmented Generation) constitue une approche prometteuse pour améliorer la traçabilité des SADC basés sur l’IA. Un outil basé sur cette technologie peut rechercher des informations pertinentes au sein d’un système (OpenEvidence p. ex. est basé sur le contenu de revues spécialisées de haut niveau telles que JAMA et NEJM). Un modèle de langage (tel que GPT) utilise ensuite ces informations pour générer des réponses précises et contextualisées. Il en résulte une réponse actuelle, fondée sur des preuves, dont on connaît l’origine. Les sources sous-jacentes s’affichent avec la réponse et il est possible de définir leur provenance (sources fiables tirées de revues spécialisées avec révision par des pairs ou bases de données créées avec ses propres contenus).
L’apprentissage fédéré offre une autre évolution prometteuse. Son intégration dans les SADC basés sur l’IA rend ces systèmes plus puissants tout en respectant la protection des données. Il s’agit d’un processus d’apprentissage automatique décentralisé qui permet d’entraîner collaborativement un modèle à partir de différentes sources de données cliniques sans jamais les partager. Chaque source entraîne le modèle localement avec ses propres données, puis partage uniquement le modèle entraîné (et non les données). Seules les mises à jour du modèle sont renvoyées au serveur central, qui les agrège pour améliorer le modèle global, créant ainsi un apprentissage collaboratif tout en protégeant la confidentialité des données.
L’Ambient clinical intelligence (ACI) soutient la prise de décision clinique en saisissant en temps réel la voix, le contexte et les données sensorielles. Les symptômes importants mentionnés lors de la discussion entre médecin et patient sont combinés aux données de santé vitales et aux informations du dossier médical informatisé et sont transmis au SADC basé sur l’IA. Le système peut ainsi fournir des recommandations en temps réel, qui peuvent ensuite être archivées de manière automatique et utilisées à des fins d’assurance qualité [4].
Conclusion
Dans la pratique, les avantages que présentent ces systèmes d’aide à la décision clinique basés sur l’IA dépendent du contexte dans lequel ils sont utilisés. L’interaction avec l’IA pose plusieurs défis, notamment en raison des limites techniques, des hallucinations et des inquiétudes suscitées par l’interprétabilité des algorithmes qui sont un obstacle pour que les médecins acceptent et se fient aux recommandations générées par l’intelligence artificielle. La technologisation croissante et l’innovation ouvrent de nouvelles perspectives pour relever ces défis. L’idée est d’aboutir à un partenariat entre l’humain et la machine dans lequel les SADC basés sur l’IA complètent, mais ne remplacent pas les capacités cognitives humaines.
Développement des SADC basés sur l’IA
Une grande quantité de données médicales (dossiers médicaux informatisés, résultats de laboratoire, données d’imagerie) sont épurées et converties dans un format compréhensible par le modèle. Celui-ci analyse les données brutes et en déduit les principales caractéristiques. Le modèle d’IA à développer est choisi en fonction de la tâche à accomplir et il est entraîné sur une partie des données. Cela lui permet d’apprendre les modèles selon lesquelles elles sont agencées et les relations entre elles dans le but de pouvoir prédire des résultats corrects (diagnostic, avertissement). L’autre partie des données est ensuite utilisée pour vérifier si le système est en mesure de performer avec des données nouvelles et inconnues. Le modèle est constamment actualisé et amélioré avec de nouvelles données. Cela permet de le tenir à jour et de l’adapter aux progrès de la médecine.
Littérature
- Zwolenski M, Weatherill L. The Digital Universe Rich Data and the Increasing Value of the Internet of Things. Australian Journal of Telecommunications and the Digital Economy. 2014 ; 2
- Bajgain B, et al. Determinants of implementing artificial intelligence-based clinical decision support tools in healthcare : a scoping review protocol. BMJ Open. 2023 ; 13
- Tai AMY, et al. Clinical decision support systems in addiction and concurrent disorders : A systematic review and meta-analysis. Journal of Evaluation in Clinical Practice. 2024 ; 30 : 1664 - 1683
- Elhaddad M, Hamam S. AI-Driven Clinical Decision Support Systems : An Ongoing Pursuit of Potential. Cureus. 2024
- Bozyel S, et al. Artificial Intelligence-Based Clinical Decision Support Systems in Cardiovascular Diseases. Anatolian Journal of Cardiology. 2024 ; 28 : 74 - 86
- Gomez-Cabello CA, et al. Artificial-Intelligence- Based Clinical Decision Support Systems in Primary Care : A Scoping Review of Current Clinical Implementations. European Journal of Investigation in Health, Psychology and Education. 2024 ; 14 : 685 - 98
- Bharmal AR. Transforming Healthcare Delivery : AI-Powered Clinical Decision Support Systems. Int J Sci Res Comput Sci Eng Inf Technol. 2025 ; 11 : 339 - 47
- Kim S, et al. Physician Knowledge Base : Clinical Decision Support Systems. Yonsei Medical Journal. 2022 ; 63 : 8 - 15
- Dingel J, et al. Predictors of Health Care Practitioners’ Intention to Use AI-Enabled Clinical Decision Support Systems : Meta- Analysis Based on the Unified Theory of Acceptance and Use of Technology. Journal of Medical Internet Research. 2024 ; 26
- Hager P, et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine. 2024 ; 30 : 2613 - 2622
- Hautz WE, et al. Diagnoses supported by a computerised diagnostic decision support system versus conventional diagnoses in emergency patients (DDX-BRO) : a multicentre, multiple-period, double-blind, cluster- randomised, crossover superiority trial. The Lancet Digital Health. 2025 ; 7 : e136-44
- Sutton RT, et al. An overview of clinical decision support systems : benefits, risks, and strategies for success. npj Digital Medicine. 2020 ; 3
- Tupsakhare P. Improving Clinical Decision Support in Health Care Through AIs. Progress in Medical Sciences. 2023 : 1-4
- Rana MS, Shuford J. AI in Healthcare : Transforming Patient Care through Predictive Analytics and Decision Support Systems. Journal of Artificial Intelligence General science (JAIGS). ISSN :3006 - 4023 2024 ; 1
- Sirajuddin AM, et al. Implementation Pearls from a New Guidebook on Improving Medication Use and Outcomes with Clinical Decision Support. Osheroff : o. J.
- Char DS, et al. Implementing Machine Learning in Health Care — Addressing Ethical Challenges. New England Journal of Medicine. 2018 ; 378
- Banerjee M, et al. The impact of artificial intelligence on clinical education : perceptions of postgraduate trainee doctors in London (UK) and recommendations for trainers. BMC Medical Education. 2021 ; 21
- Schütze D, et al. Requirements analysis for an AI-based clinical decision support system for general practitioners : a user-centered design process. BMC Medical Informatics and Decision Making. 2023 ; 23
- Tun HM, et al. Trust in AI-Based Clinical Decision Support Systems Among Healthcare Workers : A Systematic Review (Preprint). Journal of Medical Internet Research. 2024
- Neff MC, et al. Initial User-Centred Design of an AI-Based Clinical Decision Support System for Primary Care. Stud Health Technol Inform. Vol. 310, IOS Press BV. 2024, p. 1051-5
- Antoniadi AM, et al. Current challenges and future opportunities for xai in machine learning- based clinical decision support systems : A systematic review. Applied Sciences (Switzerland). 2021 ; 11
- Mittermaier M, et al. Strategies for deploying AI-based physician decision support systems : challenges and deployment approaches. npj Digital Medicine. 2023 ; 6
Sources d’information externes
© 2026, FMH Swiss Medical Association